Some Customers experiencing elevated API Errors for PubNub Presence
Postmortem
Problem Description: Starting at 02:20 PDT Feb 21, the PubNub Presence service had a sharp increase in errors (50x) and/or increased latencies. The incident was experienced in all regions, though at different frequencies/severities. The incident spanned four discrete time frames ranging in duration from 10 minutes to 30 minutes, completely resolving at 11:00 PDT on Feb 21. The incident management team responded immediately to the alert and worked through multiple phases of issue identification, mitigation, resolution, and root cause analysis. Many of the attempts at mitigation showed promising results, restoring the service at various points (as illustrated in the Impact chart below) during the incident.
Root Cause: The root cause was difficult to identify, as several distinct, seemingly unrelated, triggering events caused back pressure on the data layer, eventually causing timeouts on a code layer that runs on the data layer. Error messages from our data layer provider were not sufficient to identify the specific module causing the timeouts. After escalations and investigation, we identified the end-users sending JSON objects without constraints causing the script to fail, indeed after the evaluation fix was deployed.
Impact: Between 02:20 PDT and 11:00 PDT, there were four timeframes during which the Presence service was degraded. The incident was experienced as (a) Accuracy of presence counts, (b) an increase in 50x errors, and/or (c) increased latencies in Presence API calls returning. The specific timeframes are represented in the graph below:
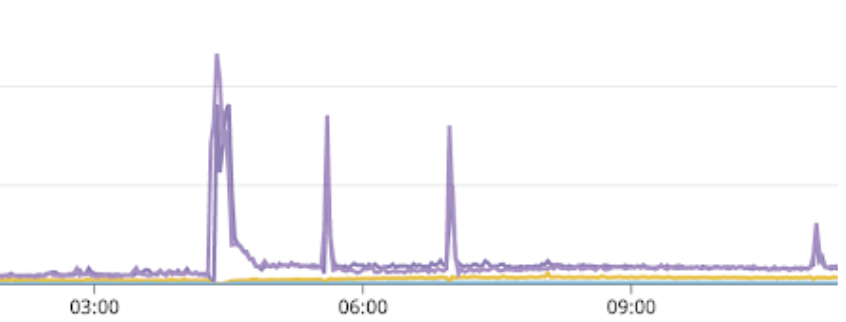
The duration of the timeframes ranged from ~10 minutes to ~30 minutes.
Mitigation Steps and Recommended Future Preventative Measures:
The main reason for the long time to fully restore was a lack of telemetry from the data layer, preventing a better understanding of the root cause and direct location of the backpressure. Preventative measures were put in place:
- Creating a process to provide the ability we give to end-users without limits and constraints.
- Working with our data layer provider, we were provided better telemetry of poorly performing modules.
- We created an updated playbook for how to detect and address any similar issues.